16 Project analysis
實際上課的期末專案使用授課教師提供的資料。期末專案的執行步驟與應達成的目標,於期中考週說明會介紹及分派專案內容。
We’ve spent the last 6 months giving you the skills you need to be able to deal with your own data. Now’s the time to show us what you’ve learned. In this chapter we’re going to describe the steps you will need to go through when analysing your data but, aside from a few lines that will help you deal with the questionnaire data that the Experimentum platform spits out, we’re not going to give you any code solutions.
Everything you need to do you’ve done before, so use this book to help you. Remember, you don’t need to write the code from memory, you just need to find the relevant examples and then copy and paste and change what needs changing to make it work for you.
We suggest that you problem-solve the code as a group, however, make sure that you all have a separate copy of the final working code. You can book into GTA sessions in week 9 and 10 to help you as well.
16.0.1 Step 1: Load in packages and data
The data file final_data.csv is on Moodle in the Group Poster section.
Don’t change ANY of the code from step 1. Just copy and paste it into R EXACTLY as it is below.
This code will clean up the Experimentum data a little bit to help you on your way. You will get a message saying NAs introduced by coercion. Ignore this message, it’s a result of converting the employment hours to a numeric variable.
It’s also worth noting that this is a MUCH larger dataset than any you’ve worked with so far and you might find that R takes a little longer to complete each task - this is perfectly normal.
library(tidyverse)
dat <- read_csv("final_data.csv",
col_types = cols(team = col_factor(),
dv = col_character()))
demo <- dat %>%
filter(quest_id == "1448") %>%
select(user_id, user_sex, user_age, q_name, dv, covid) %>%
pivot_wider(names_from = "q_name", values_from = "dv") %>%
select(-"NA") %>%
mutate(employment = as.numeric(employment))
teams <- dat %>%
filter(q_name == "team_name") %>%
select(user_id, team)
mslq <- dat %>%
filter(quest_id == "1449") %>%
select(user_id, q_name, dv) %>%
mutate(dv = as.numeric(dv)) %>%
arrange(q_name) %>%
pivot_wider(names_from = "q_name", values_from = "dv")
final_dat <- left_join(demo, teams) %>%
inner_join(mslq)Right. Your turn. You may find it helpful to use the search function in this book to find examples of the code you need.
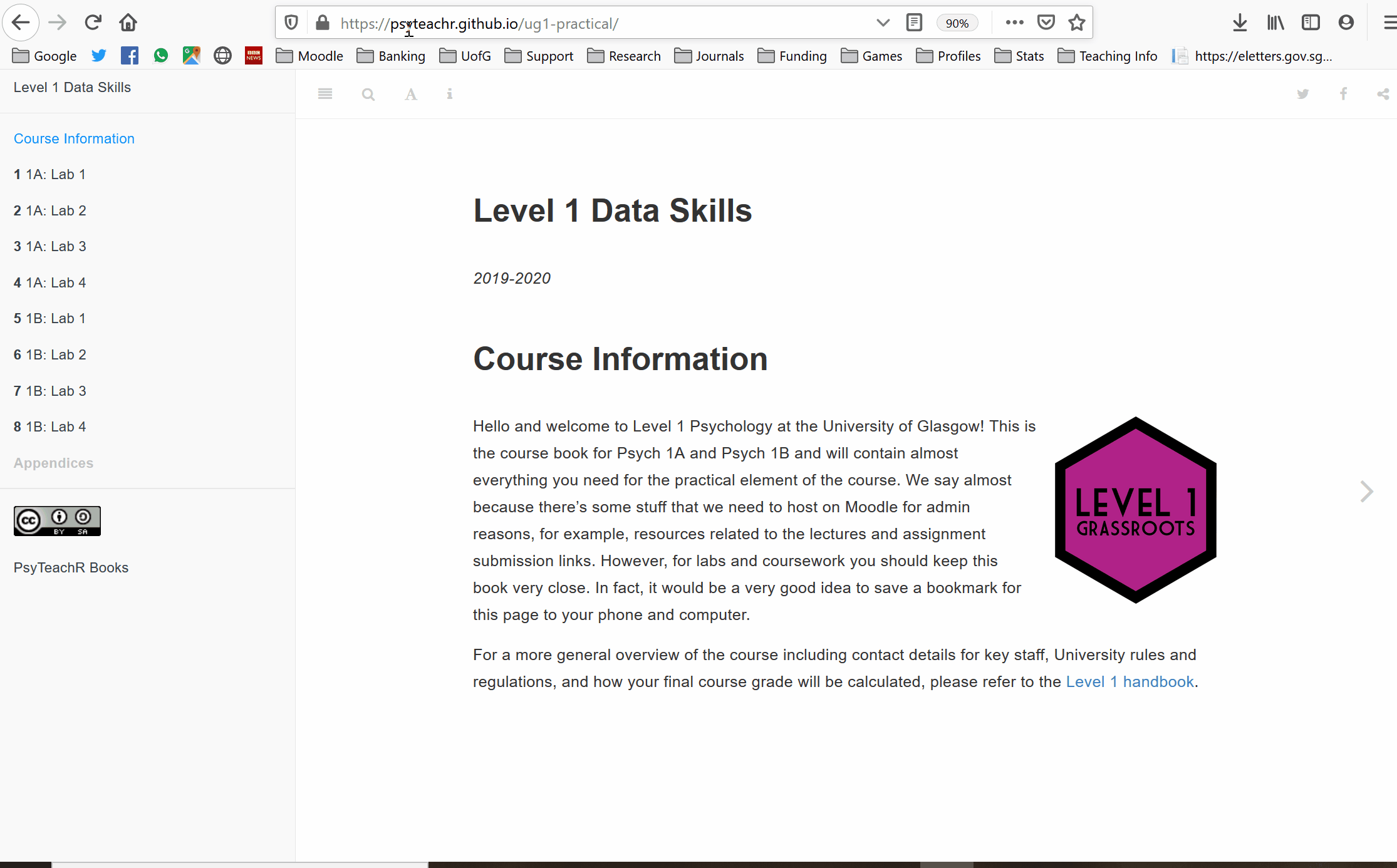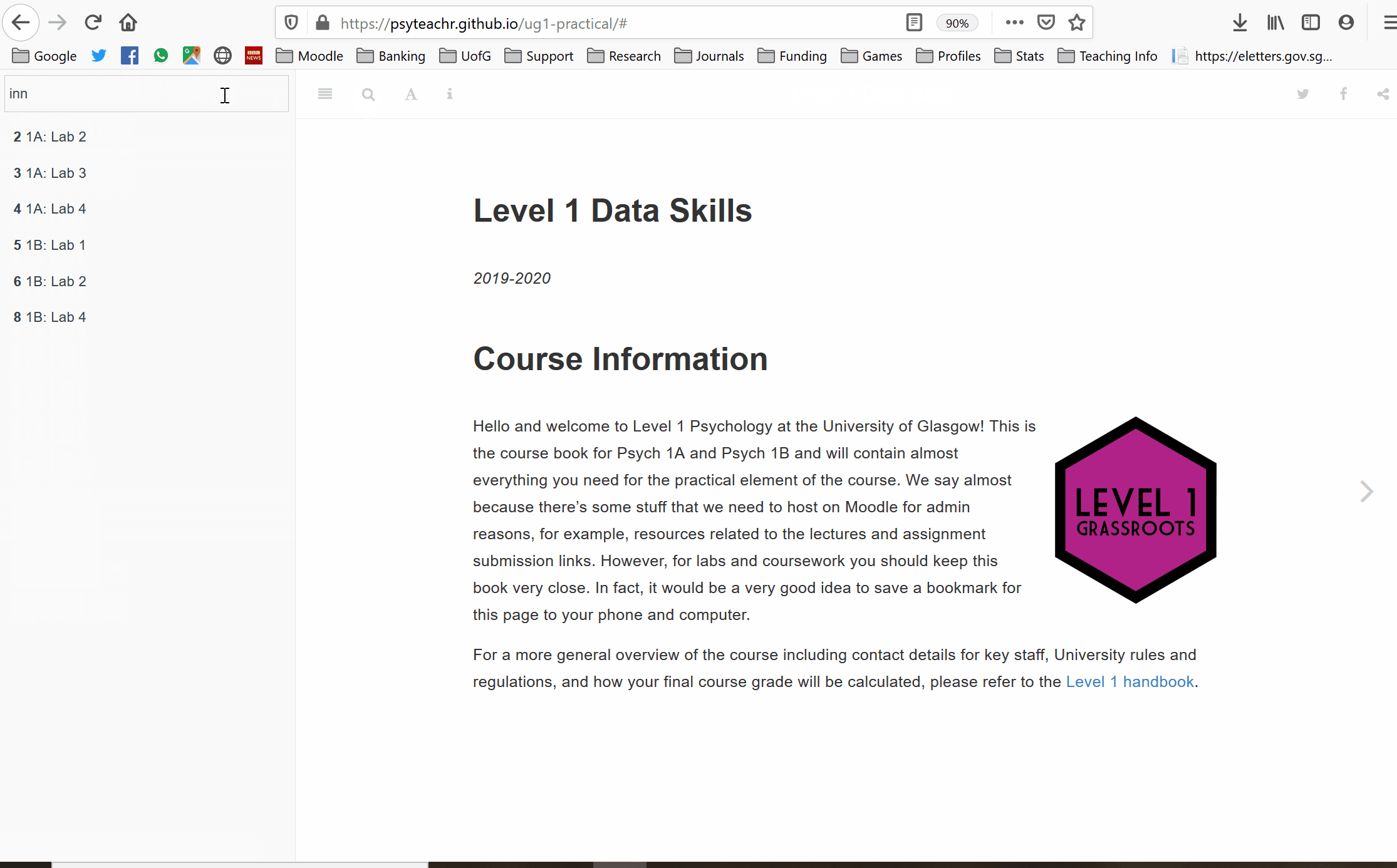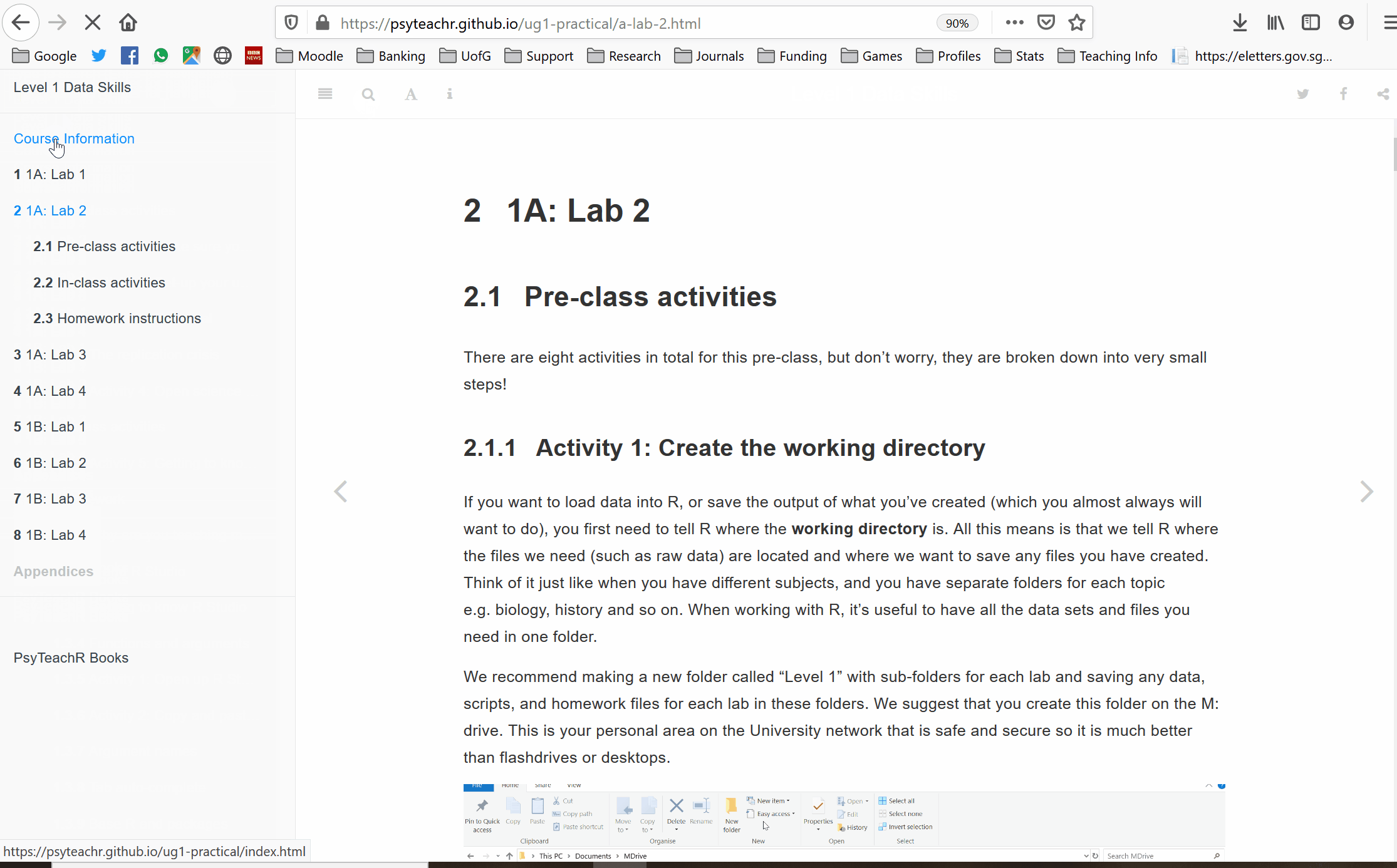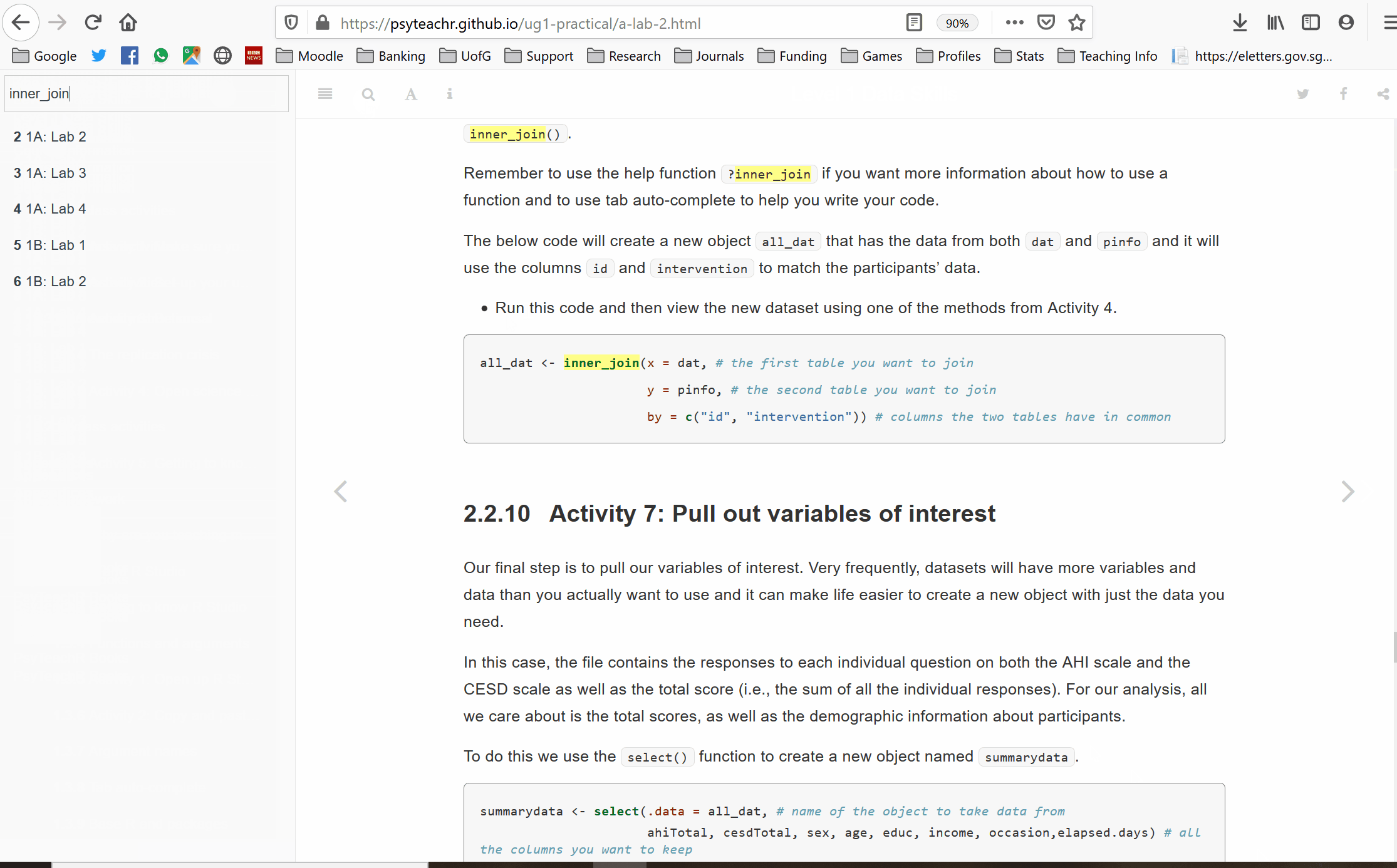
Figure 12.1: Searching for functions
16.0.2 Step 2: Look at the data
final_dat should have 91 columns which means that R won’t show you them all if you just click on the object, you’ll need to run summary(). Have a look at what all the variables are, you will find it helpful to refer to the Survey Variables Overview document.
16.0.3 Step 3. Select your variables
Use select() to retain only the variables you need for your chosen research design and analysis, i.e. the responses to the sub-scale you’re interested in as well as the user id, sex, age, team number, and any variables you’re going to use as criteria for inclusion. Again, you might find it helpful to consult the survey variables overview document to get the variable names.
16.0.4 Step 4: Factors
Using summary() again if you need it, check what type of variable each column is. Recode any variables that you want to use as categorical variables as factors and then run summary again to see how many you have in each group. You will find the code book you downloaded with the data files from Moodle helpful for this task. You may find the Data Visualisation activity about factors helpful for this.
16.0.5 Step 5: Filter
If necessary, use filter() to retain only the observations you need, for example, you might need to delete participants above a certain age, or only use mature students or undergraduate students (and make sure you kept all these columns in step 3). Do not filter the data for your team yet. You will find the code book you downloaded with the data files from Moodle helpful for this task.
If your grouping variable is whether students undertake paid employment, you will need to create a new variable using mutate that categorises participants into employed (> 0 hours worked per week) and not employed (0 hours per week) categories.
An additional bit of syntax you might find useful for this is the %in% notation which allows you to filter by multiple values. For example, the following code will retain all rows where user_sex equals male OR female and nothing else (i.e., it would get rid of non-binary participants, prefer not to says, and missing values).
dat %>%
filter(user_sex %in% c("male", "female"))You can also do it by exclusion with !. The below code would retain everything where user_sex DOESN’T equal male or female.
dat %>%
filter(!user_sex %in% c("male", "female"))If you were feeling really fancy you could do steps 2 - 5 in a single pipeline of code.
16.0.6 Step 6: Sub-scale scores
Calculate the mean score for each participant for your chosen sub-scale. There are a few ways you can do this but helpfully the Experimentum documentation provides example code to make this easier, you just need to adapt it for the variables you need. You may also want to change the na.rm = TRUE for the calculation of means depending on whether you want to only include participants who completed all questions.
- Change
datato the name of the object you created in step 6 - Change
question_1:question_5to the relevant variables for your subscale e.g.,help_1:help_4 - Change
scale_meanto the name of your sub-scale e.g.,anxiety_mean - If you want to calculate the mean scores for participants who have missing data, e.g., if they only completed three out of four questions for your sub-scale, then
na.rm = TRUE. If you only want to calculate scores for participants who answered all questions for your sub-scale, thenna.rm = FALSE. - Change NOTHING else
You may get the message summarise() regrouping output by.... this is fine.
dat_means <- data %>%
pivot_longer(names_to = "var", values_to = "val", question_1:question_5) %>%
group_by_at(vars(-val, -var)) %>%
summarise(scale_mean = mean(val, na.rm = TRUE)) %>%
ungroup() Optional: If you want a dataset that just has complete cases, then you can run the below code. This will remove any participants who have an NA for scale-score due to missing data.
dat_means_complete <- dat_means %>%
drop_na(scale_mean)16.0.7 Step 7: Split the dataset
Use the codebook to find which team number corresponds to your team. Next, use filter() to create a new dataset that only contains the data from participants who contributed to your team and call it dat_means_team. Once this is complete, you will have a final large dataset that contains the sub-scale scores for all participants, and a smaller dataset that just has data from the participants you recruited for your team.
16.0.8 Step 8: Demographic information
That should be the really hard bit done, now you’ve got the data in the right format for analysis.
First, calculate the demographic information you need: number of participants, gender split, grouping variable split (if you’re using a variable that’s not gender), mean age and SD.
You can calculate mean age and SD using summarise() like you’ve done before. There’s several different ways that you can count the number of participants in each group, we haven’t explicitly shown you how to do this yet so we’ll give you example code for this below. The code is fairly simple, you just need to plug in the variables you need.
Do this separately for the full dataset and your team dataset.
# count the total number of participants in the dataset
dat_means %>%
count()
# count the number of responses to each level of user_sex (for gender)
dat_means %>%
group_by(user_sex) %>%
count()
# count the number of responses to each level of covid status (change this variable to the one you're using if necessary)
dat_means %>%
group_by(covid) %>%
count()
# count the number of responses across two categories (you might not need or want to do this)
dat_means %>%
group_by(user_sex,covid) %>%
count()Once you’ve done this you might realise that you have participants in the dataset that shouldn’t be there. For example, you might have people who have answered “Not applicable” to the mature student question, or you might have some NAs (missing data from when people didn’t respond).
You need to think about whether you need to get rid of any observations from your dataset. For example, if you’re looking at gender differences, then you can’t have people who are missing gender information. You may have said in your pre-reg that you would only include non-binary people if they made up a certain proportion of the data. If you’re looking at mature student status, you can’t have people who didn’t answer the question or who said not applicable (i.e., postgrad students). You need to decide whether any of this is a problem, and potentially go back and add in an extra filter to step 6.
16.0.9 Step 9: Descriptive statistics
Use summarise() and group_by() to calculate the mean, median, and standard deviation of the sub-scale scores for each group. Do this separately for the full dataset and your team dataset.
16.0.10 Step 10: visualisation
You now need to create a bar chart with error bars and a violin-boxplot for both the full dataset and your team dataset. You’ve done all of these before, just find a previous example code and change the variables and axis labels. If you are comparing pre and post-covid, then you team plot will only have data from the post-covid group, this is ok, you can still compare it to the larger sample.